這篇演講筆記是2026-05-02 應中華編劇學會邀請發表的演講,主題在針對文科職業編劇們,讓他們理解AI的核心與創意的拉扯,並如何在人工智慧海嘯下,保守最重要的創意核心,建立自己的創作知識庫。
AI海嘯下的編劇生存指南 v3
AI 的浪潮已經來了,但我們真正需要的不是追上每一個新工具,而是搞清楚 AI 的本質是什麼、它的限制在哪裡。演講將從大語言模型的原理出發,討論 AI 在劇本創作上的實際應用與常見誤區,並深入探討潛台詞、原創性等編劇核心能力為何是 AI 無法取代的。最後提供具體的工具與方法,幫助編劇建立自己的 AI 協作流程。

一、海嘯是真的,但我們搞錯了問題
要不要用AI,是假議題。
就像當年問要不要用電腦寫劇本、要不要上網查資料、要用數位還是膠捲拍電影一樣——這個問題的答案不重要,因為海嘯不等你決定。
班佛列克說他的公司正在把整個電影製作流程AI化。重點不是AI取代了哪個職位,而是整個工業的工作方式正在被重新定義。
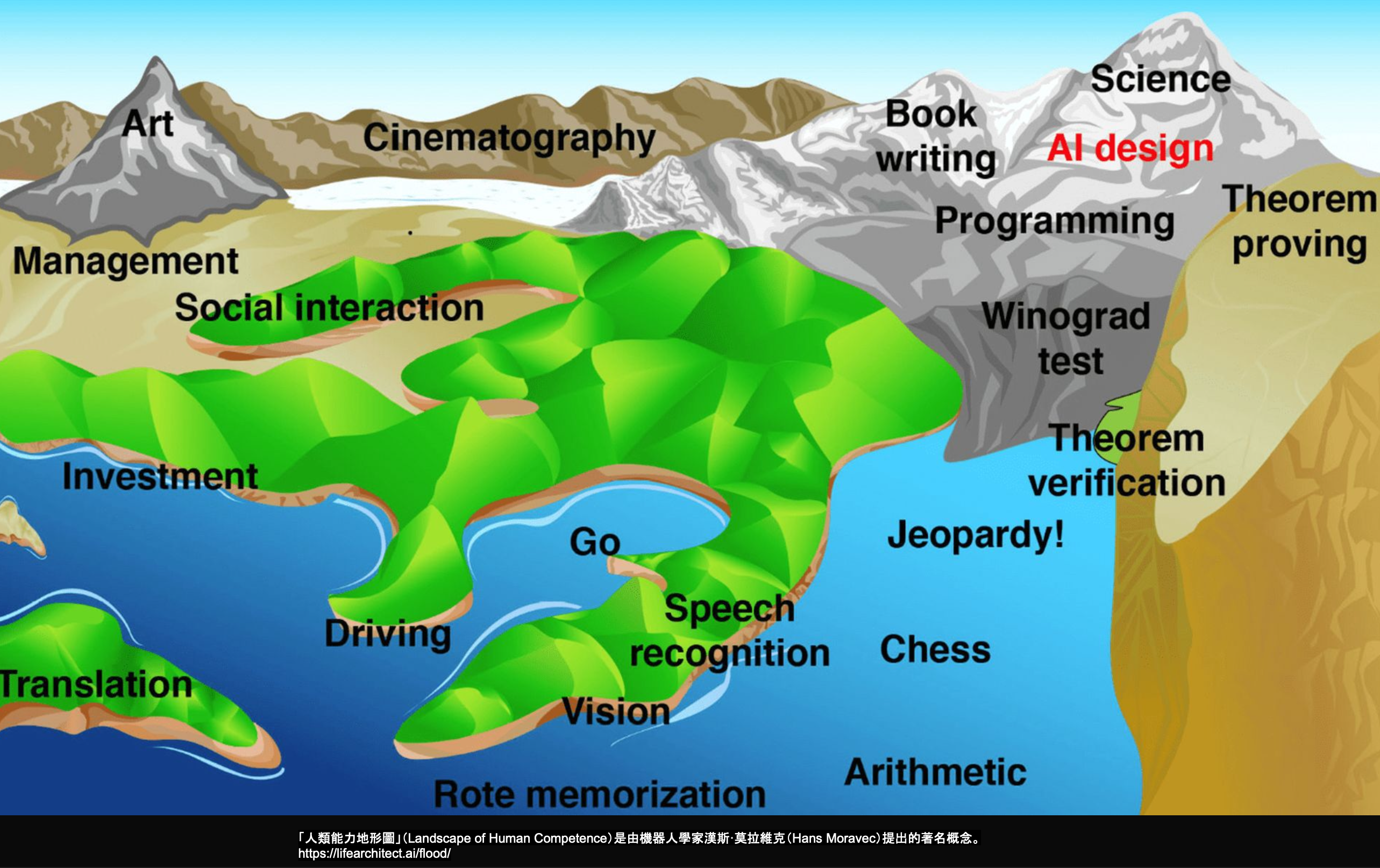
人類能力地形圖
機器人學家漢斯·莫拉維克(Hans Moravec)提出的「人類能力地形圖」(Landscape of Human Competence)是個很好的視覺化工具。把人類各種能力想像成一片地形——水平面就是 AI 已經淹過的能力線。
過去幾年我們親眼看著水位上升:翻譯、語音辨識、圍棋、寫程式、考試解題……一個個被淹沒。Cinematography、Book writing、Art、AI design 這些山頭,現在還露在水面上,但水位還在漲。
這張地圖的意義不是「哪些工作會消失」,而是讓你看清——你以為高聳的山頭,其實只是還沒被淹到的小丘。
對齊(Alignment)
我今天準備的演講,不是跟一群電影系的學生、社群媒體行銷人員或短影音創作者,談怎麼快速生成AI短劇,而是跟一群職業編劇,分享AI的基本觀念和使用心得。這在AI領域術語,叫做「對齊 Align」。先把對話脈絡界定清楚,彼此的溝通才會聚焦。
我不談如何3小時快速生成AI影片。 今天站在這裡,也不是當個AI傳教士,也不是末日預言家,我覺得真正想問、該問的問題,只有一個:
做為一個文字創意工作者,到底怎麼面對這劇變?
(更具體一點:如何將AI整合進我的工作流程?)
AI 焦慮的三個來源
開始之前先承認一件事——我們之所以坐在這裡,多少都帶著一點焦慮。我把這份焦慮分成三種:
- 職業替代的恐懼——我會不會被取代?
- 創意的流失與風格抹平——就算沒被取代,我會不會慢慢變得跟 AI 一樣?
- 資訊與技術的過載——每天幾十支「你一定要學會這個工具」的影片,永遠追不完。
這三種焦慮的解藥都不是「學更多 AI 工具」。而是回頭搞清楚 AI 的本質。
二、AI是什麼——大語言模型是怎麼練出來的
我們需要回頭去理解的,是AI的本質到底是什麼。搞清楚了本質,你就不會再被每一個新工具嚇到,你也才能真正判斷它能幫你做什麼、不能替你做什麼。
大語言模型LLM的本質
所以讓我來跟大家解釋一下,到底什麼叫做大語言模型(Large Language Model)。
大凡,所有的人工智慧系統,主要的功能或任務,都是「預測」。特斯拉的自動駕駛,要預測下一秒該往哪邊走,才能戴乘客安全抵達目的地;AlphaGo,要預測下一手棋要下在哪裡才能贏過對手;圖片生成AI要預測下一個pixle要如何生成,才能呈現完美的照片。
我們編劇最常使用的對話AI,例如ChatGPT、Gemini、Claude,都叫做大語言模型。
而,大語言模型(LLM)的核心任務只有一個:「如何預測下一個字?」
說穿了,就是一個超級複雜的文字接龍遊戲。
預測可以很簡單,例如,我說「藍天」,你腦海裡就出現「白雲」。我打字打了一個「台」,後面有90%機率會出現「灣」這個字。說穿了,就是一個統計機率問題。像這兩個例子,都是單維的判斷,用一個簡單的統計分析,就能夠有八成的準確度。
但要做出一個「好」的預測,卻很困難,因為人類語言的多樣性、彈性,從一個字、一個詞,到一篇完整的文章,可能性就馬上勁升到天文數字。怎麼講、怎麼排列組合都有可能。那該如何解決?
這問題本質上是在設計出一個「可以說話具備語言能力的人工智慧系統」,這個問題困擾了人工智慧學者超過80年。一直沒找到解決方案。
直到,大語言模型,這個全新的技術概念誕生了。
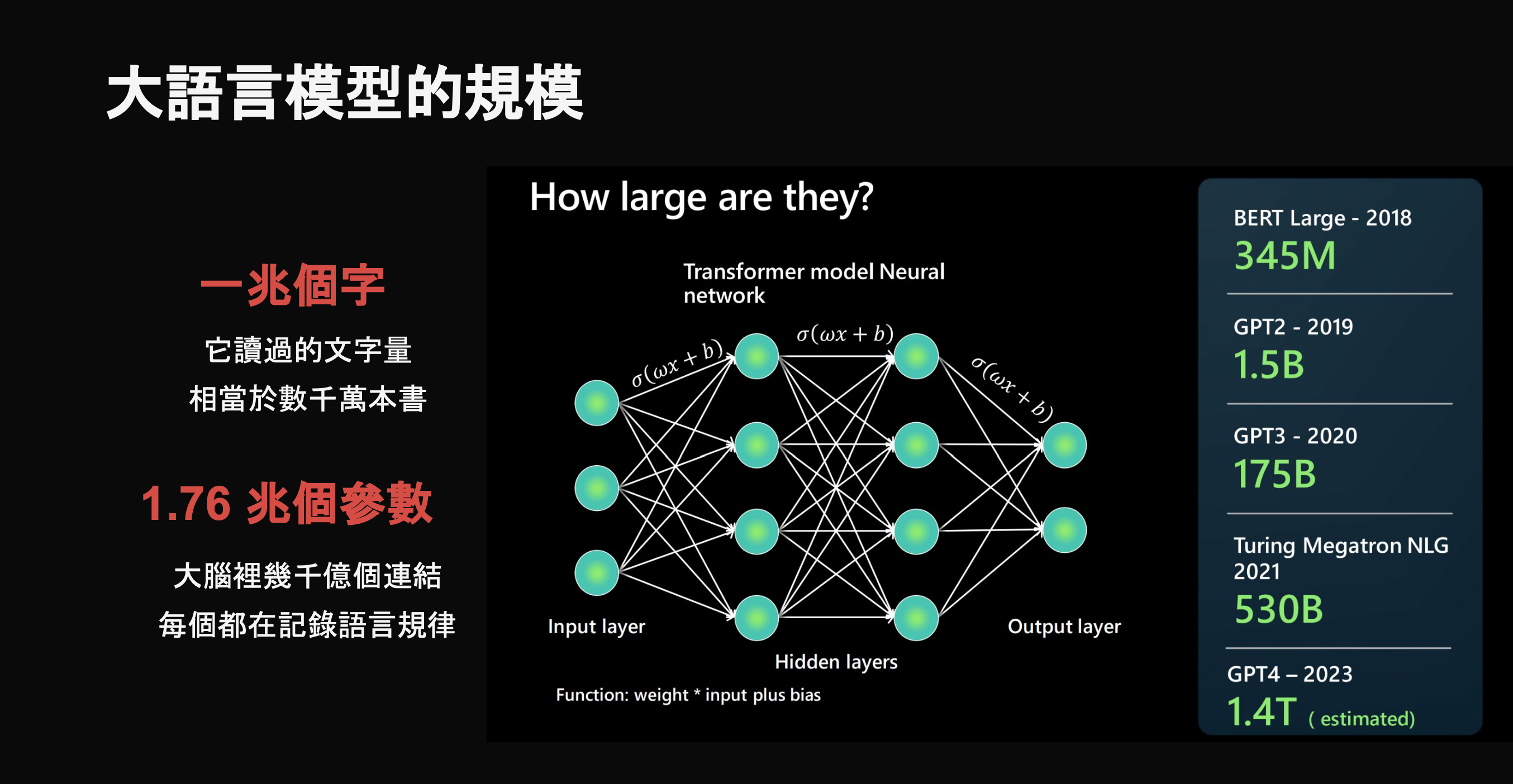
大語言模型的規模
三個數字讓你感受它的規模:
- 一兆個字——它讀過的文字量,相當於數千萬本書
- 1.76 兆個參數——可以想成大腦裡幾千億個連結,每一個都在記錄語言的規律
- 一億美元以上——訓練一個頂級模型的成本,這就是為什麼只有少數大公司做得到
模型規模的演進也很驚人:BERT Large(2018)3.45 億 → GPT-2(2019)15 億 → GPT-3(2020)1750 億 → Turing Megatron NLG(2021)5300 億 → GPT-4(2023)估計 1.4 兆參數。
而這個規模還在以指數速度成長。2019年的GPT-2用了40GB的訓練資料,幾年後的GPT-3是570GB,現在的模型已經幾乎涵蓋人類所有的數位文字。這不是線性成長,是每隔幾年就翻天覆地。
我不打算講Transformer架構或技術細節。你們不需要知道引擎怎麼運作,你們需要知道這台車有幾個輪子,會往哪個方向走。
三、LLM 的兩個核心觀念
LLM很複雜,但對我們編劇而言,我覺得有兩個核心觀念是最重要的:
- 沒有記憶
- 尋找模式
核心觀念一:LLM 沒有記憶
這是最違反直覺的一點。每次你打開 ChatGPT、Claude,跟它對話,模型本身沒有任何記憶。它不記得昨天你跟它聊過什麼,甚至不記得三分鐘前你說的話。每一次對話都是全新的開始。
那它怎麼好像「記得」我們的對話?
答案是——它不是真的記得,是每次對話前,把整個對話脈絡重新塞給它看一次。AI 看到的「目前對話脈絡」,是這三樣東西組合起來的:
- System Prompts / User Input(設定 AI 的角色)
- User Input(你的輸入)
- 對話串(歷史紀錄)
每一次你按下送出,整包重塞一次。所以管理「給它看什麼」,就成了使用 AI 最重要的技能。等下會講到。

核心觀念二:LLM 是尋找模式的機器
AI的訓練過程,讀遍了人類寫過的所有故事、所有的劇本、所有的電影,所以它知道所有的套路。它永遠能給你一個答案——結構正確、類型清晰、幾乎不會犯錯。什麼三幕劇、英雄旅程、佛洛依德、榮格,他都背得出來,他都知道,但也都不知道。
說穿了,LLM模型(還有其他不同的AI模型)是個超級複雜的「文字接龍遊戲」,他預測的方式不是來自於理解文本的意義,而是文字間的模式與關係。這是我說他看不懂的意思。
因此,它非常擅長模式匹配——找出語言裡的規律,知道什麼樣的故事結構最常出現,什麼樣的對白符合觀眾期待。這是它的能力,也正是它的極限。
這個能力,在某個面向來說,和編劇正好相反,我們不喜歡浮上腦海的第一個念頭、順理成章的邏輯,我們創造衝突、享受意外、強化轉折、說謊、殺人。
戲就是衝突、衝突,每一場戲都是衝突。LLM本能的很討厭衝突。這是埋在它骨子裡、訓練裡的天性裡。
我們的工作從來不是給出「夠用的」答案。我們的工作,是找到那個只有這個故事才有的答案。
尋找模式 vs 原創——AI 沒有活過
這裡要特別談原創性的問題。
AI做的是模式匹配,它永遠在找最可能、最常見、最符合規律的答案。但偉大的創作往往是打破規律——是那個出乎意料、讓人心裡一震的時刻。
AI能寫出一個合格的劇本,但它寫不出只有你才能寫出來的那個故事。
你的生命經驗、個人視角、對人性的洞察——這些是AI無法訓練出來的,因為AI 沒有活過。它只認識已經被寫下來的人,不認識真實的人。
風格可以被模仿,但原創性來自於你是誰,你經歷過什麼,你對世界有什麼獨特的看法。 這件事,AI永遠搶不走。
整理可以委託,理解不能外包
AI是你個人意識的鏡子,一個放大鏡。
你給它什麼脈絡,它就反映什麼。你給它空的,它給你的就是最大公約數。
很多創意,就是來自於你親自坐下來,讀那些訪談、文獻、故事的過程。不是讀完之後得到的結論,而是讀的過程本身浮現的——某一句話讓你突然想到什麼,某一個細節讓你感到不對勁,某一個人說話的方式讓你想起了另一個人。
這個「突然想到什麼」,是你的故事為什麼和別人不一樣的原因。AI可以幫你整理一百份訪談,讓你更快找到需要的資料。這很好,這是委託。但如果你讓AI替你「理解」這些訪談,你得到一份摘要,你就失去了那個「突然想到什麼」。
整理可以委託,理解不能外包。
那些越來越像在「破解演算法」的劇本——不是被AI寫壞的,是被AI替代了理解的過程。
四、我的 AI 做什麼?
說完原則,講具體用法。我把 AI 的角色分兩層:
工作助理:表層應用
這層大家比較熟悉:
- 翻譯(這領域 RIP 了)
- 整理逐字稿、會議紀錄
- 資料整理、快速查詢、生產摘要
- 快速打樣!! ——這是表層應用裡最被低估的一項。第一輪文字潤飾要小心(見下面 AI 味),但拿來模擬、試水溫、看看「如果這樣寫會長什麼樣」,非常好用。打完樣之後,那份初稿你要敢丟掉,不是拿來用的。
創意夥伴:真正價值
這層才是分水嶺:
1. 最有耐心的讀者
把你的角色設定、故事背景告訴它,讓它扮演你最忠實而嚴格的觀眾。即時反應、討論,而不是兩個星期後,才和導演、製作人用10分鐘討論你苦思了十幾天的完整內容。讓它站在不同觀眾的立場給你讀後感。
2. 最了解我的對話夥伴
讓它跟你辯論——「為什麼觀眾應該在乎這個角色?」
但要小心:演算法的天性很容易妥協、附和、安慰、讚同你,強化你自己喜歡的部分,隱藏弱點。 你要主動逼它反對你。
3. 最嚴格的劇本醫生
AI熟悉劇本結構,熟悉影視產業邏輯,很容易可以協助分析判斷你的初稿劇本問題可能在哪裡,並提出改善建議。注意,這是對初稿而言,進階的程度,AI還不太做得到。我個人很少滿意AI給我的改善建議。
4. 靈活多變的角色扮演
讓AI飾演你的劇中角色,對話辯論。這就是「馬戲團 / 即興劇場」——你寫的角色,第一次有了能跟你頂嘴的機會。
五、你的第一步——為 AI 建立對話脈絡
和AI的對話,就像是遠端作業,給一個專家顧問來討論。他如果不了解你的故事脈絡,討論就流於浮面。
現在主流的AI工具——ChatGPT、Gemini、Claude——Web介面都提供兩個關鍵功能:
自訂 AI 人格(System Prompt)
你可以設定AI在這個專案裡扮演什麼角色——比如「你是一個有二十年經驗的資深編劇,專門幫我找故事邏輯的漏洞」,或是「你是一個挑剔的台灣觀眾,對家庭倫理劇有很深的感情」。同樣的問題,不同的人格設定會給你完全不同角度的回應。
但,還是要記得,這是角色扮演,不要以為你叫他扮演村上春樹,他就真的變成村上春樹了。AI寫不出村上春樹的小說(至少到目前為止)。
Project(專案)
你可以為每個劇本建立一個獨立的專案,把角色資料、故事核心、參考脈絡全部上傳進去。之後在這個專案裡的所有對話,AI都記得你的故事背景,你不需要每次重新解釋。
Context Window 上下文窗口
這裡要插一段技術觀念,因為它直接決定你怎麼用 AI。
Context Window 是大語言模型的「短期記憶」——AI 所「見」的所有資訊,包含你的輸入(Input)和它的輸出(Output),全部裝在這個窗口裡。以 Tokens 為計量單位(一個 token 大約是一個英文單字,或半個中文字)。
現在頂級模型的 Context Window 已經到 1M tokens,相當於可以一次塞進一整套《魔戒》。聽起來很大,但有四個陷阱:
- Information Overload——資料太多會淹沒模型,反而降低專注力
- Getting Lost in Data——大窗口會優先處理首尾,漏掉中間的關鍵資訊(這叫 Lost in the Middle)
- Poor Management——資料越多,雜訊、冗餘、偏誤都會增加
- Long-Range Issues——窗口越大,理解資料之間長距離關係反而更難
所以「丟越多越好」是錯的。 學會操縱上下文窗口——什麼時候該開新對話、什麼時候該把舊脈絡濃縮、什麼資料該放進 Project、什麼資料當下貼進來——是進階使用 AI 最關鍵的功夫。

六、第二步:建立屬於你自己的創作知識庫——第二大腦
要建立和AI對話的脈絡,接下來說一件更重要的事——你需要建立一個讓AI真正能進入你故事的環境,也就是個人的創作知識庫。
為什麼要做這件事?三個理由:
- 個人的創作歷史積累——你寫了二十年的東西不應該散在一百個 Word 檔裡
- 知識複利——筆記之間建立連結,舊筆記會主動撞出新想法
- 讓 AI 真正進入你的脈絡——光有個人資料,AI 只知道你「是誰」;當你認真記錄自己怎麼思考,AI 拿到的是你創作的 DNA
大家也不要被「個人知識庫」這個現在網路上很熱門的流行詞彙給嚇到,它其實沒那麼神秘,沒那麼複雜,而且,老實說,你們每個人都已經有這個東西了,存在你們的檔案資料夾裡面。
劇本知識庫的四大要素
-
角色資料:每個主要角色一份文件。不只是基本資料,而是他的核心傷痛、欲望、說話方式、和其他角色的關係。越具體,AI給你的對白越像這個人,而不是一個通用的電視角色。
-
故事核心:這個故事在說什麼?主題是什麼?你希望觀眾看完之後有什麼感受?這是你和AI協作的錨點,每次對話前先讓它看這份文件,它就不會跑偏。
-
參考資料:田野訪談重點、你喜歡的參考作品和原因、你收集的真實事件或新聞素材。
-
劇本草稿:故事大綱、長綱、分集綱、對白本。
Obsidian / PARA 架構
先說一個大家都心知肚明的事——你們現在用什麼工具管理劇本資料?大部分的答案是Word。
傳統 Word:為了「列印」而設計。
問題是,大家就這樣用Word管角色小傳、存田野筆記、寫會議記錄——然後桌面上出現「劇本final、劇本final2、劇本真的final、劇本0927改版」。
這不是笑話,這是我們影視圈的日常。
問題是AI很不喜歡讀Word檔。
推薦使用Obsidian(或 Notion、Bear 這類工具)。
Obsidian:為了「思考」而設計。
- 網狀連結:角色與情節可以建立雙向連結
- 純文字 Markdown:極輕量、永久保存、易遷移
- AI 友善格式:可以把整個資料夾丟給 AI
用PARA架構(由 Tiago Forte 提出的知識管理方法論)來組織:
- P(Projects):正在開發的劇本(有結束時間)
- A(Areas):長期關注的題材(沒有結束時間)
- R(Resources):持續收集的參考(不需要時間)
- A(Archives):已完成的封存(不再需要)
Obsidian是你的長期知識庫,ChatGPT或Claude的Project是每次工作的協作介面——兩者分工,互不取代。你的創作積累,真正屬於你自己。
這和編劇的工作直接相關。你的角色小傳、田野筆記、故事核心——如果只是堆在資料夾裡,AI 拿到的是資料。如果用心整理成你真正思考的方式,AI 拿到的是你創作的 DNA。

對話 讓思考外部化
寫筆記、跟 AI 對話、為角色寫小傳——這些動作表面上是「整理資料給 AI 看」,但真正發生的事其實是:讓思考外部化。
你以為你想清楚了,當你必須把它說給另一個(哪怕是矽基的)對象聽,你才會發現你哪裡其實沒想清楚。AI 最有用的時候,不是它給你答案的時候,是它逼你把問題說完整的時候。
七、你現在的用法,可能正在傷害你的寫作
我看到三個讓我擔心的現象:
現象一:用AI生成「夠用的」初稿
一部60分鐘的影集,16000個字,AI可以兩天幫你填滿。但AI沒辦法替你想清楚這16000個字的核心情節。你自己沒想清楚,就會變成湯湯水水——結構齊全,但空洞。
我自己的使用經驗是:AI可以幫你很快改完整個初稿,這是真的。你知道你要什麼,它就幫你快速執行。但如果你自己還不清楚方向,它就會幫你快速製造垃圾——16000個字,全部填滿,全部是空的。
AI的速度是雙面刃。你夠清楚,它幫你快。你不清楚,它幫你快速製造垃圾。
人類的腦袋很懶惰,AI也很懶惰。AI快速打出樣稿,你很容易說服自己,好像完成了。就放棄再嘗試書寫或思考更不一樣的可能性。
市場上、網路上,正在快速被浮濫的垃圾內容淹沒。這是趨勢、現實,我不想說它好或壞,但這不是我今天要跟一群職業編劇討論的議題。
現象二:AI味,是真的
AI生成的文字有一種特定的節奏和措辭習慣,非常容易辨認。這不是文學品味、也不是你的錯覺,這是數學模型。
現在已經有工具可以偵測一篇文章是不是由AI寫的。 它的偵測原理和AI生成文字的原理一樣——都是用數學模式去分析這段文字的規律。AI寫出來的文字在統計上有特定的模式,太平滑、太正確、太符合預期,這些特徵都會被偵測出來。
所以,有人就開發出新的AI,可以幫你把文字改寫成沒有AI味,然後,檢測AI再升級… WTF。
我必須說,在其他領域,例如論文、法律、醫囑,AI會快速進入,所有的制式邏輯文字都會由AI來協助產生。這沒什麼不對。但對「創作者」,我們而言,面對的問題不太一樣。
AI味的問題其實分兩層:
第一層是個人風格被抹平。每個編劇的文字都有自己的氣質——有人寫得克制,有人寫得濃烈,有人對白很精準,有人擅長留白。這些風格是你多年積累出來的,是你的聲音。AI會把這些磨平,把你的文字修整成一種「標準好讀」的樣子。潤飾一次你可能感覺不出來,但一直用下去,你的聲音就慢慢消失了。
第二層是角色失去個性。一個好劇本裡,每個角色說話的方式應該完全不同——你蒙住名字,光看對白就知道是誰在說話。但AI傾向於讓所有角色說表面、流暢、正確的話。結果是每個人聽起來都差不多,都得體、流暢、正確——然後你記不住任何一個人。這種劇本結構完整,但你記不住任何一個人。
大家要記得,當製作公司、電視台、或評審開始使用這類工具的時候,一份AI味太重的劇本會直接被標記。這不是未來的事,這件事現在已經在發生了。
現象三:用AI閱讀資料、篩選題材、審核劇本
這是我見過最危險的誤用。
AI 篩出來的,永遠是最符合慣例的劇本。
AI會給高分給那些符合慣例、類型清晰的劇本。那些結構不尋常、沉默多過對白、風格強烈的劇本——AI不知道如何評價。如果你的劇本要先通過AI的篩選才能到人的手上,你需要知道這件事。
現在這件事正在蔓延到影視產業。我開始注意到有製作人在用AI來做劇本的初步判讀——讓AI先篩一輪,再決定要不要給人看。這對整個產業是非常危險的發展。因為AI篩出來的,永遠是最符合慣例的劇本。那些真正有原創性、有獨特視角、敢於打破類型慣例的作品,會在第一關就被過濾掉,永遠到不了真正懂得欣賞它的人手上。
我們正在用 AI 殺掉影視創作的多樣性,而且很多人還沒有意識到這件事。
八、AI帶不走的那件事
說了那麼多AI能做什麼、不能做什麼,最後我想說回我們。
編劇這個職業,最核心的功課從來只有一件事:
說你自己的故事
或者,說一個千百年不變的愛情故事——但用一個從來沒有人用過的方式來說它。
這件事,AI永遠做不到。
因為AI讀遍了人類所有寫下來的故事,所以它知道所有說過的方式。它能給你一個正確的愛情故事,一個符合類型慣例的愛情故事,一個觀眾看了不會不舒服的愛情故事。
但那個「從來沒有人這樣說過」——只能來自你。來自你活過的人生,你見過的人,你在某個時刻突然想到的那個角度。
AI是一面鏡子,它反映你給它的東西。你給它空的,它給你最大公約數。你給它你真正想說的故事,它幫你把它說得更清楚。
所以海嘯來了,你最好的武器不是學會用最多的AI工具。而是更清楚地知道——你想說什麼,只有你能說什麼。
它(還)不會玩的文字遊戲
舉例來說,有四個編劇最核心的技巧,是 AI 目前真正做不到的:
潛台詞——沒被說出的話,才是真的。一個母親說「你吃飽了嗎」,真正想說的是「我愛你,我怕失去你」。AI 天然趨向於把話說滿,它不習慣留白。
反台詞——說反話的時候,他在藏什麼。「我不在乎」,但他其實在乎得要命。這需要對人性有深刻理解,知道人在什麼情境下會說反話,背後藏著什麼。
謊言——說謊的方式,比真話更揭露一個人。一個角色說謊的方式,往往比他說真話更能揭露他是什麼樣的人。AI 很難寫出有說服力的謊言,因為它需要同時理解「真實是什麼」和「為什麼要隱藏真實」。
埋梗——那個翻轉瞬間的情感衝擊。在前面鋪墊某種細節,到最後才做出翻轉與揭露,讓觀眾心頭一震。AI 是線性生成文字的,它感受不到那個翻轉瞬間對觀眾應該有多大的情感衝擊。
這四個技巧有一個共同點——它們都依賴對「說出來」和「不說出來」之間那個空間的掌控。那個空間,是編劇最珍貴的創作領域,也是 AI 目前最難進入的地方。
九、今天回去,做一件事
不用全部都做,選一個你今天就能開始的。
入門 | 五分鐘 打開ChatGPT或Claude,建立一個新的Project,把你現在正在開發的劇本和一段故事簡介放進去。就這樣。你的AI協作空間今天就存在了。
進階 | 一小時 為你最重要的一個角色,寫一份真正給自己看的人物小傳——不是給製作公司的那種,而是寫清楚他為什麼是這樣的人,他最深的傷是什麼,他說話的方式和別人有什麼不同。把這份小傳放進你的Project,下次讓AI幫你寫對白的時候,看看有什麼不同。
最根本 | 一張紙 拿一張紙,寫下:「這個故事只有我能寫,因為……」 把它貼在你的工作桌前面。 如果你答不出來,那就是你今天真正需要解決的問題。不是AI的問題,是你的問題。
十、Q & A:現在,直接跟 AI 對話
讓我的AI助理HAL9000參與,即時互動問答。
*(結尾回到開場:「我在準備這場演講的時候一直在用AI。你現在看到的這份稿子,是我和AI來回打磨出來的。但這場演講想說什麼,是我自己想清楚的。那個部分,我沒有外包。」)
